


Layout LM explained - paper reading
Layout LM
In this article I’ll share my notes on the paper LayoutLM: Pre-training of Text and Layout for Document Image Understanding by Yiheng Xu et. al.
In this paper, the authors have suggested a noval way (when it was published) to address document AI problems like
- Visual document classification
- Visual document information extraction (otherwise token classification task)
Document AI refers to techniques for automatically reading, understanding, and analyzing business documents or visual documents in general. Visual documents are electronic documents like a reciept or pdf document or photograph of an ID card.

Introduction
The work on BERT [1] showed than pre-training of transformer models can help improve quality of NLP tasks significantly. A pre-trained BERT model could be finetuned for several tasks including token classification or text classification.
The authors of Layout LM have shown that for visual documents using 2D spatial embedding and image embeddings along with the original token embedding and 1D position embedding leveraged in transformer [2] can help improve performance for document AI tasks.
When the paper was published the authors claimed it to be SOTA for
- Form understanding (from 70.72 to 79.27)
- Receipt understanding (from 94.02 to 95.24)
- Document image classification (from 93.07 to 94.42)
Architecture
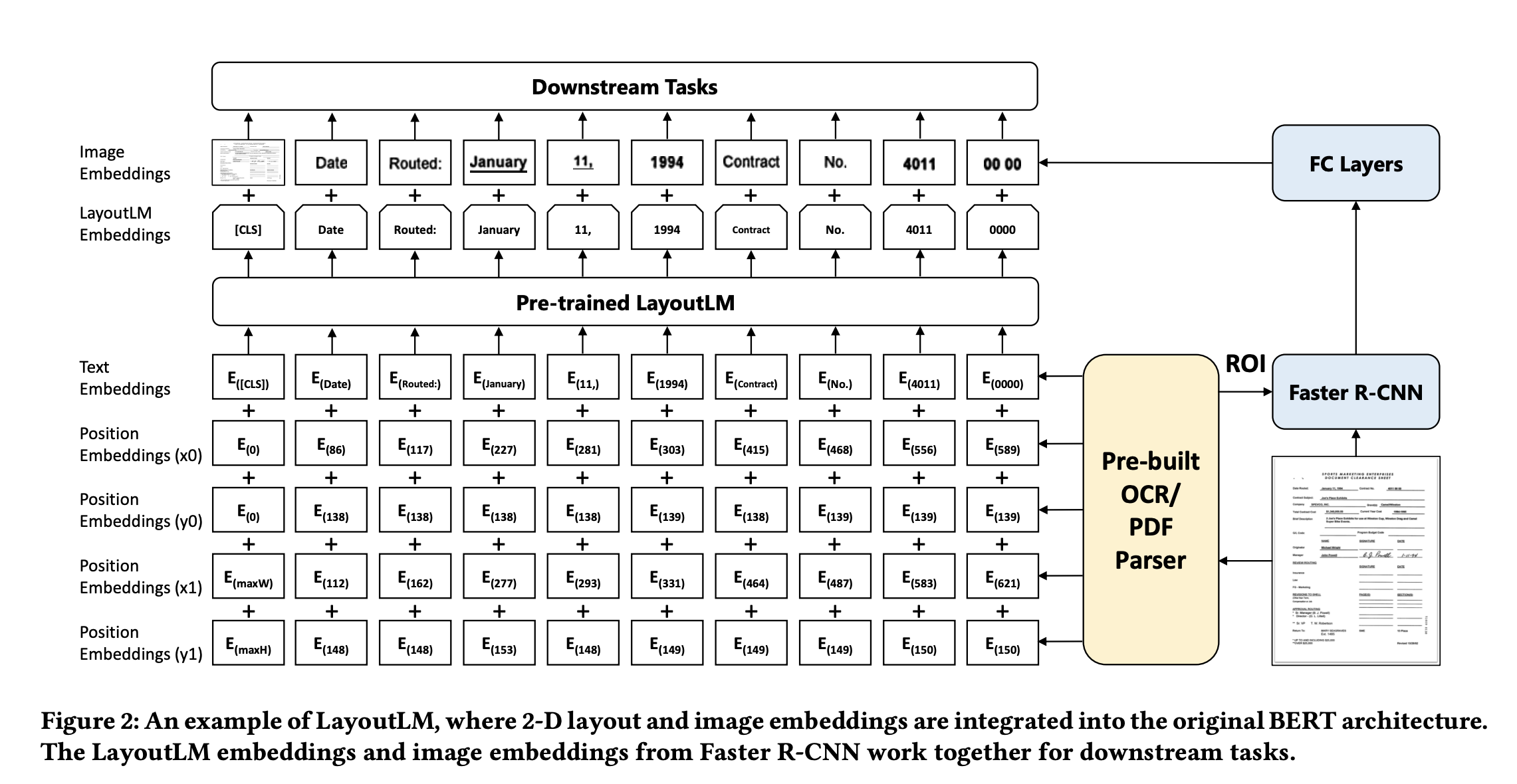
- Text embedding similar to BERT, uses WordPeice tokenizer.
- For position embedding, the two corners of the bounding box for each token is used.
- Let’s call top left to be
(x0, y0)& bottom right to be(x1, y1). - Two embeddings are learned for each axis (
x&y). - The values are normalized and scaled to
[0, 1000]range. - Per codebase on Github, it looks like embedding is computed for
width&heightof the bounding box as well. Also, 1D position embedding seems to be computed as well.
- Let’s call top left to be
- Image embeddings are computed using pre-trained models like
Faster R-CNN, and used for fine-tuning.
Key points
BERT Architecture + Spatial Layout Embedding
- BERT has already shown immense success for NLP tasks.
- Hypotheis: Adding layout information and pretraining with visual documents with relevant objectives would help improve the results observed for visual document understanding tasks.
- A 2-D position embedding denotes the relative position of a token within a document.
- BERT model is pretrained with two objectives
- Masked Language Modeling (MLM): k %age of tokens masked and model has to predict the token.
- Next Sentence Prediction (NSP): For two given sentenses, model has to predict if sentense B comes after sentense A (binary classification task).
Image Embedding
- Hypothesis: The image embeddings can help encode relevant image information for text tokens like
font directions,types, andcolors. These have relevance to document understanding. - A visual document is first OCRed which gives text tokens and their bounding boxes. Image features are generated for each token using faster R-CNN models.
- For
[CLS]token the whole image is used as input to faster R-CNN model.
Pre-training objectives
Objectives
- Masked Visual-Language Model (MVLM): Randomly mask some of the input tokens but keep the corresponding 2-D position embeddings, and then the model is trained to predict the masked tokens given the contexts. In this way, the LayoutLM model not only understands the language contexts but also utilizes the corresponding 2-D position information, thereby bridging the gap between the visual and language modalities.
-
we select 15% of the input tokens for prediction. We replace these masked tokens with the [MASK] token 80% of the time, a random token 10% of the time, and an unchanged token 10% of the time. Then, the model predicts the corresponding token with the cross-entropy loss.
-
- Multi-label Document Classification (MDC): Model is pretrained with MDC loss as well.
Model initialization
Two models are trained: BASE and LARGE.
| # | Transformer Layers | Hidden Sizes | Attention Heads | # params |
|---|---|---|---|---|
| Base | 12 | 768 | 12 | 113M |
| Large | 24 | 1024 | 24 | 343M |
Training Info
- Trained on: 8 NVIDIA Tesla V100 32GB GPUs
- Batch size: 80
- Optimiser: Adam, initial learning rate
5e-5, a linear decay learning rate schedule. - Time to pretrain (11M docs): 80hrs for
Base, 170hrs forLarge.
Fine tuning
- Form and receipt understanding tasks: LayoutLM predicts
{B, I, E, S, O}tags for each token and uses sequential labeling to detect each type of entity in the dataset. - Document image classification task: LayoutLM predicts the class labels using the representation of the
[CLS]token.
Results
TL;DR;
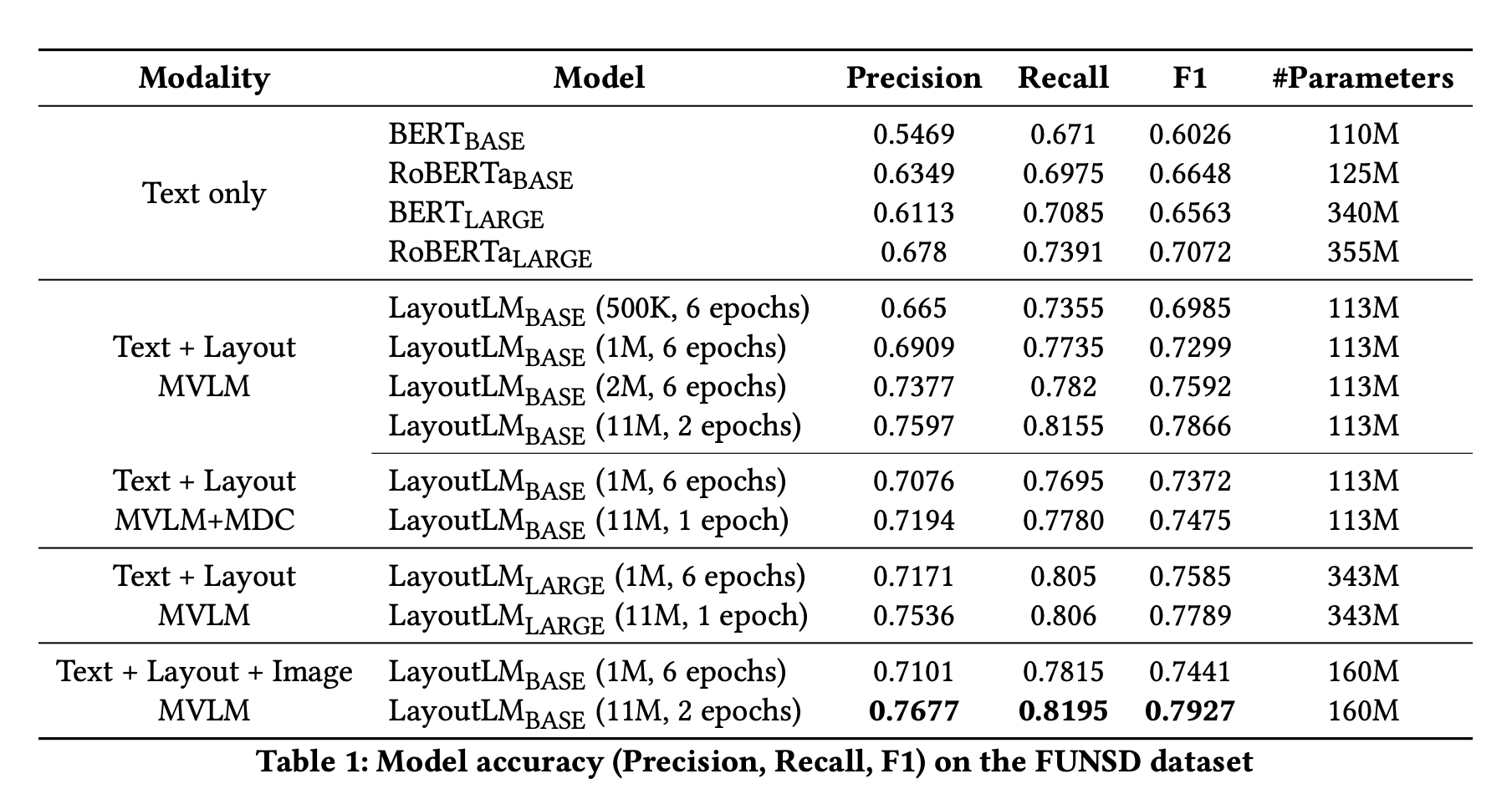
- On
FUNSD,Text + Layout + Image MVLMperformed best with F1 of0.7927.- Best performance on
LayoutLM Base (160M params), 11M data, 2 epochs. Text + Layout MVLMbest result was withLarge (343M), 11M data, 1 epoch. F1 score =0.7789.Text + Layout MVLMbest result was withBase (113M), 11M data, 2 epoch. F1 score =0.7866.
- Best performance on
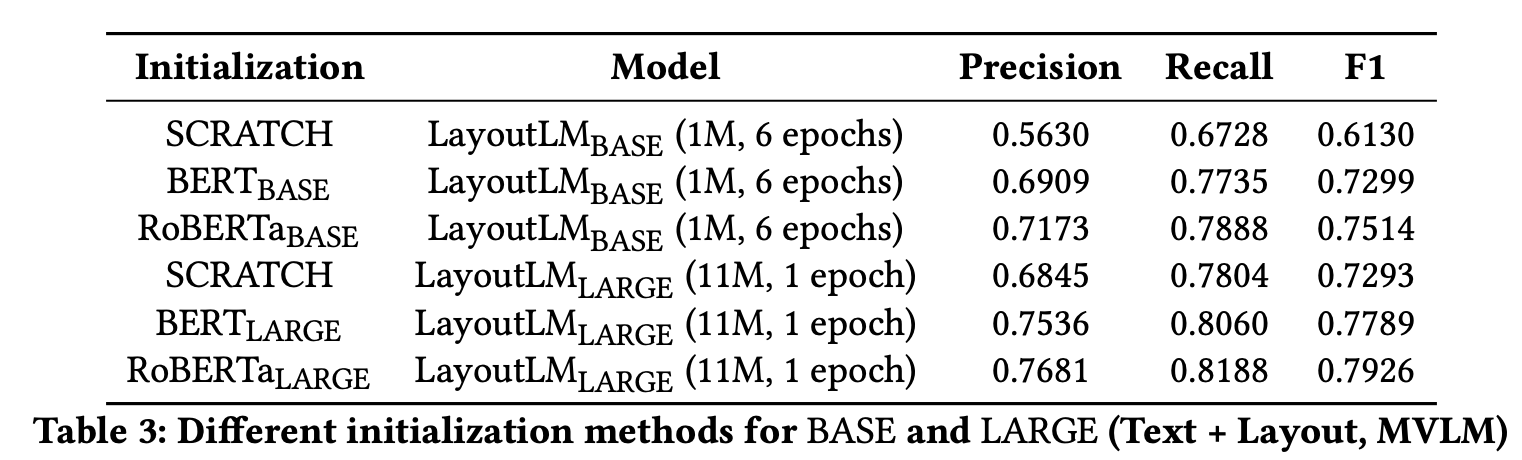
- Initializing with
RoBERTagave better results thanBERTor no initialisation for bothBaseandLargeLayout LM models. - For
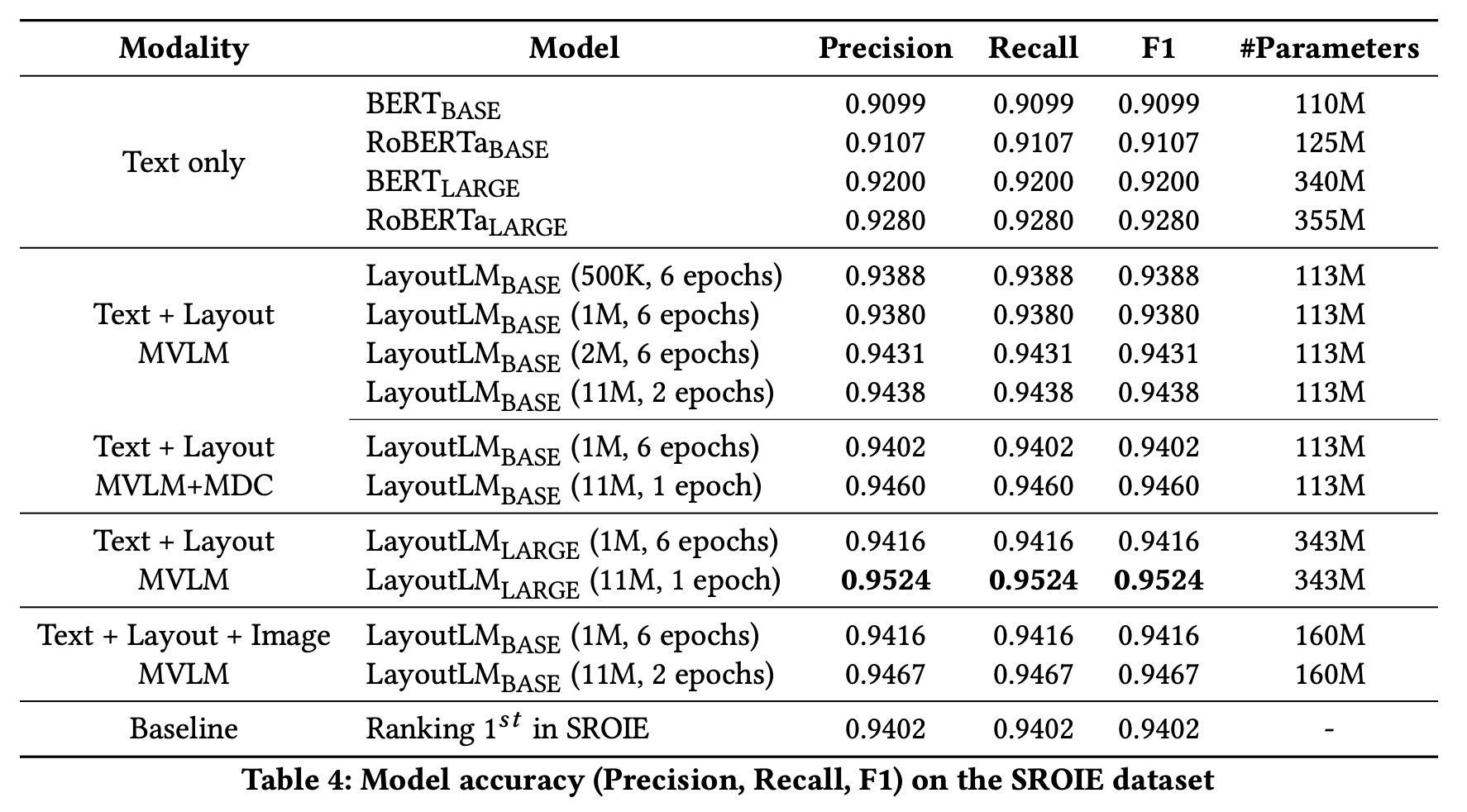
SROIE,Text + Layout MVLM, Large (343M), 11M data, 1 epochperformed best with F1 score of0.9524.Text + Layout + Image MVLM, Base (160M), 11M data, 2 epochperformed close enough with F1 score of0.9467.
- For
RVL-CDIP,Text + Layout + Image MVLM, Base (160M), 11M data, 2 epochsperformed best with94.42%accuracy.
Images / Figures from the paper
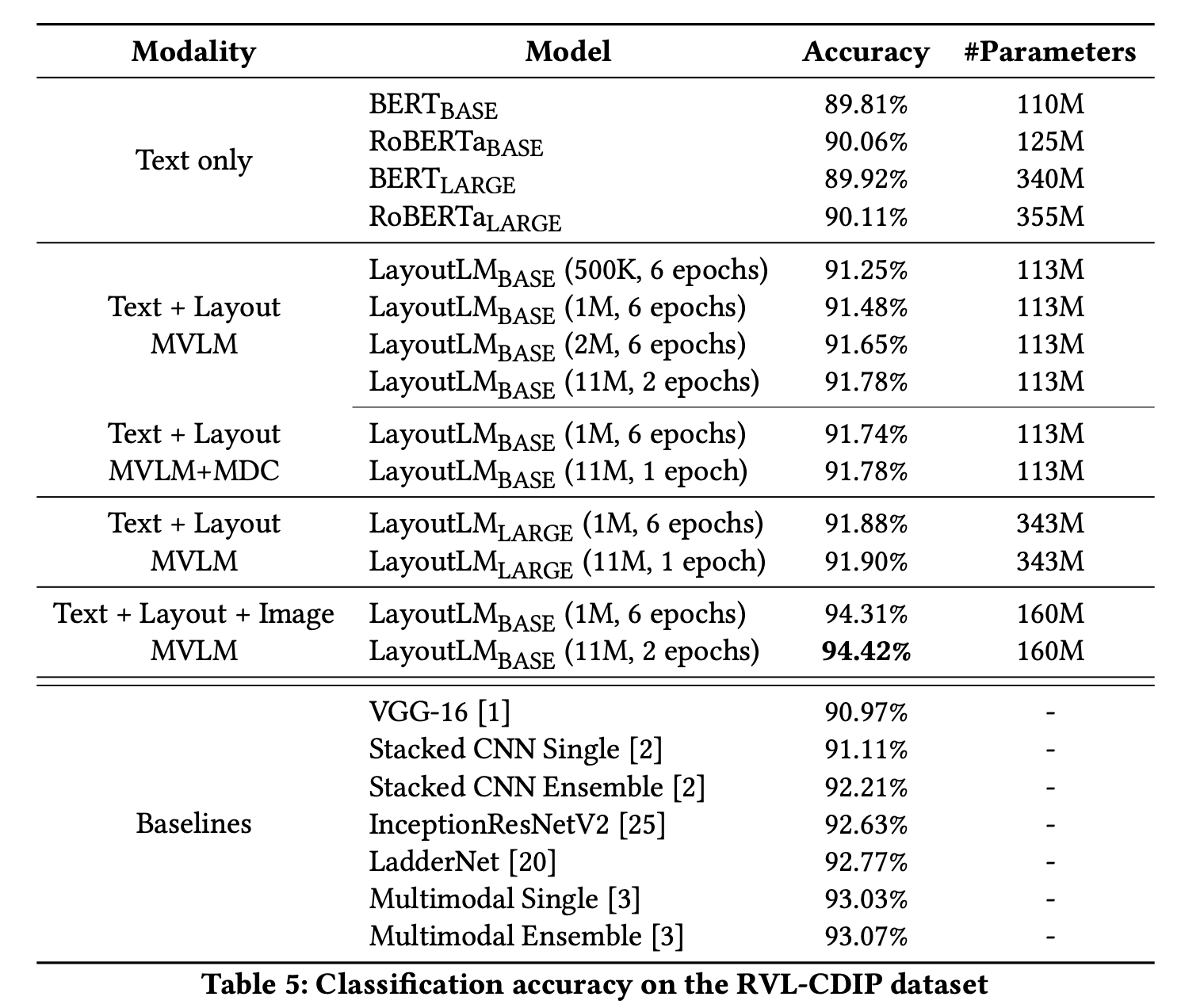
Dataset used
For pre-training
- IIT-CDIP: contains 6 million scanned documents with 11 million scanned document images.
- The scanned documents are in a variety of categories, including letter, memo, email, filefolder, form, handwritten, invoice, advertisement, budget, news articles, presentation, scientific publication, questionnaire, resume, scientific report, specification, and many others, which is ideal for large-scale self-supervised pre-training.
For fine-tuning
- FUNSD dataset: spatial layout analysis.
- SROIE dataset: Scanned Receipts Information Extraction.
- RVL-CDIP: Document image classification - consists of 400,000 grayscale images in 16 classes.
Paper credits
LayoutLM: Pre-training of Text and Layout for Document Image Understanding by
- Yiheng Xu, Harbin Institute of Technology
- Minghao Li, Beihang University
- Lei Cui, Microsoft Research Asia
- Shaohan Huang, Microsoft Research Asia
- Furu Wei, Microsoft Research Asia
- Ming Zhou, Microsoft Research Asia
Other references
Want to read more such similar contents?
I like to write articles on topic less covered on internet. They revolve around writing fast algorithms, image processing as well as general software engineering.
I publish many of them on Medium.
If you are already on medium - Please join 4200+ other members and Subscribe to my articles to get updates as I publish.
If you are not on Medium - Medium has millions of amazing articles from 100K+ authors. To get access to those, please join using my referral link. This will give you access to all the benefits of Medium and Medium shall pay me a piece to support my writing!
Thanks!